AI RAN is moving to the center court. While operators have not fundamentally changed how they think about their RAN roadmaps—openness, intelligence, automation, and virtualization remain the core pillars of next-generation RAN platforms—the visibility and adoption of these technologies vary significantly. In the early phase of 5G, Open RAN and vRAN dominated the conversation. Today, AI RAN is the shiny object.
Events such as MWC2026 Barcelona and Nvidia GTC reinforced the message we have communicated for some time, namely that AI RAN is already happening. At the same time, the GPU conversation is shifting. Looking ahead, AI RAN is expected to see broad adoption across the RAN in the latter half of the 5G cycle and from the outset of 6G.
All roads lead to increased adoption of AI RAN. Differences will emerge across deployment models, compute architectures, hardware choices, functional splits, and underlying technologies.
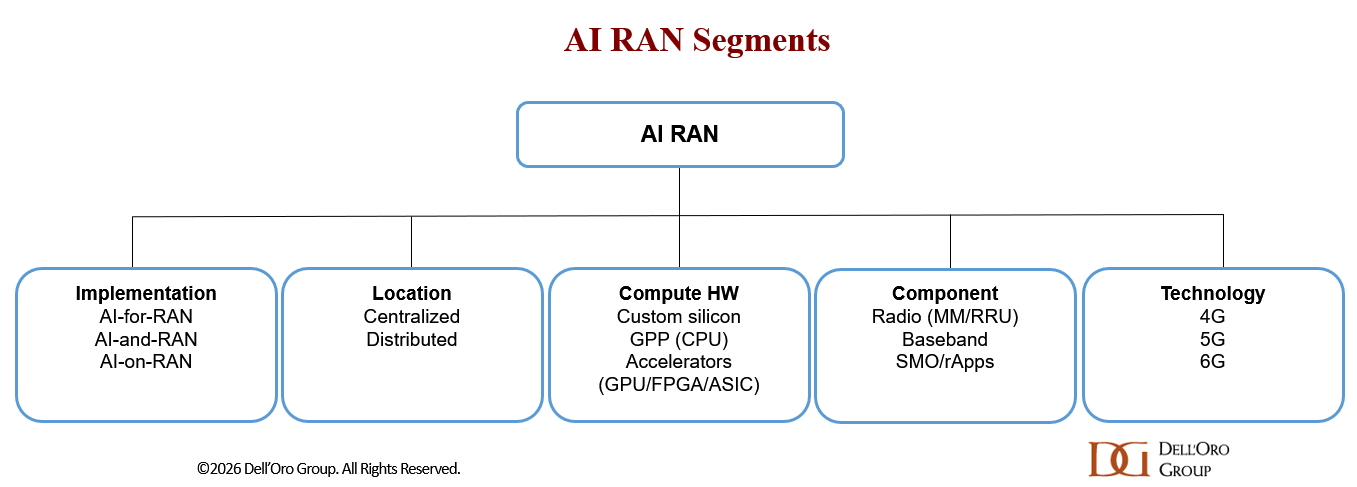
At present, the majority of the AI RAN market is driven by distributed AI-for-RAN solutions focused on improving performance and efficiency, often leveraging existing 5G infrastructure. Vendors such as Huawei and ZTE have collectively shipped more than 0.6 M AI-enabled boards/plug-ins, underscoring that AI RAN is already happening at scale.
One of the key takeaways from MWC Barcelona is that nearly all RAN roadmaps—across both large and smaller vendors—now incorporate AI RAN capabilities across the full RAN stack, with a focus on AI-for-RAN. And it is not just the baseband—suppliers are now bringing intelligence into every RAN layer, including the radios. Ericsson’s launch of ten AI-ready radios featuring in-house silicon with neural network accelerators is a case in point. The question is no longer if AI RAN and AI-RAN will happen, but rather how, what, where, and when.

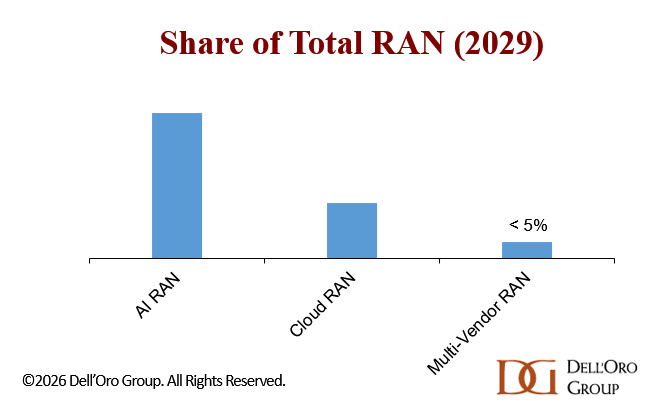
Dell’Oro’s long-term view of next-generation RAN has remained broadly intact. Events like MWC 2026 and NVIDIA GTC have done little to alter the underlying trajectory. The likelihood that AI RAN, Cloud RAN, and multi-vendor RAN will play major roles in the second half of 5G and the early 6G era remains high, moderate, and low, respectively. According to our latest forecast update, AI RAN is expected to surpass $10 B and account for roughly one-third of the total RAN market by 2029 (this is not new revenue).
Within the AI RAN domain, the prospects for GPU-RAN (and AI-and-RAN) are improving—still small, but no longer negligible. This shift reflects both low starting expectations and a gradual change in sentiment. The conversation is moving from outright skepticism to cautious curiosity. Much of this momentum is being driven by NVIDIA’s continued push and its vision that the world’s ~10 million macro sites could evolve into more than just base stations. As Jensen Huang put it during his GTC keynote: “That base station…is going to become an AI infrastructure platform.”
Early operator progress—from T-Mobile, SoftBank, and Indosat—combined with Nokia’s recent reiteration of its AI-RAN roadmap, is reinforcing this shift. Samsung and 1Finity, meanwhile, are exploring whether GPUs could make sense to diversify their computing platforms.

Part of the renewed interest in AI RAN—and GPU RAN specifically—stems from a broader realization: technological change is accelerating at a much faster pace than during the 4G-to-5G transition. This shift is reshaping how the industry views the role of mobile networks, the distribution of AI inference, and the trade-offs between hardware-based and software-defined architectures.
At the same time, “physical AI” is becoming more tangible. Concepts that once felt like science fiction—such as robots assisting with cooking or walking children to school—are now increasingly plausible in the near term.
That said, operators remain cautious for now about GPU RAN and broad-base AI inference distribution, even as skepticism gradually eases as the ecosystem matures. The constraints are structural. RAN deployments operate under tight power budgets, strict cost controls, and massive scale requirements. These factors make it challenging to justify deploying power-intensive compute at every cell site.
So, concerns persist about the performance-per-watt gap between GPUs and custom silicon, as well as the practicality and need to support non-telco workloads at both D-RAN and C-RAN sites—particularly in D-RAN deployments. For example, the SoftBank/Ericsson robot assistance demo at MWC operated with latency requirements of around 100 ms, which allows for centralized AI inference, with compute resources located in a data center using the User Plane Function.
In other words, AI RAN is moving from hype toward reality. While trade-offs across AI inference distribution needs, flexibility, performance, energy efficiency, TCO, and TTM will shape adoption paths over the near-term and long-term, the overall direction is clear: AI will become an integral part of every layer of the RAN.
Base-case projections suggest that non-GPU RAN will dominate AI RAN over the forecast period, reflecting both the ability to upgrade existing infrastructure, the constraints at the cell site, and the need for multi-purpose tenancy. This suggests NVIDIA still faces a meaningful challenge if it aims to position itself not only as the “inference king,” but also as the “AI RAN king.”
At the same time, the conversation is clearly evolving. Operators are no longer asking why GPUs might be relevant, but rather where and when they make sense. If NVIDIA succeeds in expanding the role of the RAN—from a single-purpose connectivity layer into a distributed AI platform—the long-term opportunity could be significantly larger than what is currently reflected in our base-case assumptions. As Amara’s Law suggests, the risk may not be overestimating the short-term impact of AI RAN, but underestimating the demand for more distributed intelligence over the long-term.