Across hyperscalers and sovereign clouds alike, the race is shifting from just model supremacy to infrastructure supremacy. The real differentiation is now in how efficiently GPUs can be interconnected and utilized. As AI clusters scale beyond anything traditional data center networking was built for, the question is no longer how fast can you train? but can your network keep up? This is where emerging architectures like Optical Circuit Switches (OCS) and Optical Cross-Connects (OXC), a technology used in wide area networks for decades, enter the conversation.
The Network is the Computer for AI Clusters
The new age of AI reasoning is ushering in three new scaling laws—spanning pre-training, post-training, and test-time scaling—that together are driving an unprecedented surge in compute requirements. At GTC 2025, Jensen Huang stated that demand for compute is now 100× higher than what was predicted just a year ago. As a result, the size of AI clusters is exploding, even as the industry aggressively pursues efficiency breakthroughs—what many now refer to as the “DeepSeek moment” of AI deployment optimization.
As the chart illustrates, AI clusters are rapidly scaling from hundreds of thousands of GPUs to millions of GPUs. Over the next five years, the expectation is that there will be about 124 gigawatts of capacity to be brought online, or an equivalent of more than 70 million GPUs to be deployed. In this reality, the network will play a key role in connecting those GPUs in the most optimized, efficient way. The network is the computer for AI clusters.

Challenges in Operating Large Scale AI Clusters
As shown in the chart above, the number of interconnects scales exponentially with the number of GPUs. This rapid increase drives significant cost, power consumption, and latency. It is not just the number of interconnects that is exploding—the speed requirements are rising just as aggressively. AI clusters are fundamentally network-bound, which means the network must operate at nearly 100 percent efficiency to fully utilize the extremely expensive GPU resources.
Another major factor is the refresh cadence. AI back-end networks are refreshed roughly every two years or less, compared to about five years in traditional front-end enterprise environments. As a result, speed transitions in AI data centers are happening at almost twice the pace of non-accelerated infrastructure.
Looking at switch port shipments in AI clusters, we expect the majority of ports in 2025 will be 800 Gbps. By 2027, the majority will have transitioned to 1.6 Tbps, and by 2030, most ports are expected to operate at 3.2 Tbps. This progression implies that the data center network’s electrical layer will need to be replaced at each new bandwidth generation—a far more aggressive upgrade cycle than what the industry has historically seen in front-end, non-accelerated infrastructure.
![]()
The Potential Role of OCS in AI Clusters
Optical Circuit Switches (OCS) or Optical Cross-Connects (OXC) are network devices that establish direct, light-based optical paths between endpoints, bypassing the traditional packet-switched routing pipeline to deliver near-zero-latency connectivity with massive bandwidth efficiency. Google was the first major hyperscaler to deploy OCS at scale nearly a decade ago, using it to dynamically rewire its data center topology in response to shifting workload patterns and to reduce reliance on power-hungry electrical Ethernet fabrics.
A major advantage of OCS is that it is fundamentally speed-agnostic—because it operates entirely in the optical domain, it does not need to be upgraded each time the industry transitions from 400 Gbps to 800 Gbps to 1.6 Tbps or beyond. This stands in stark contrast to traditional electrical switching layers, which require constant refreshes as link speeds accelerate. OCS also eliminates the need for optical-electrical-optical (O-E-O) conversion, enabling pure optical forwarding, that not only reduces latency but also dramatically lowers power consumption by avoiding the energy cost of repeatedly converting photons to electrons and back again.
The combined benefit is a scalable, future-proof, ultra-efficient interconnect fabric that is uniquely suited for AI and high-performance computing (HPC) back-end networks, where east-west traffic is unpredictable and bandwidth demand grows faster than Moore’s Law. As AI workload intensity surges, OCS is being explored as a way to optimize the network.
OCS is a Proven Technology
Using an OCS in a network is not new. It was, however, called by different names over the past three decades: OOO Switch, all-optical switch, optical switch, and optical cross-connect (OXC). Currently, the most popular term for these systems used in data centers is OCS.
It has been used in the wide area network (WAN) for many years to solve a similar problem set. And for many of the same reasons, tier-one operators worldwide have addressed it through the strategic use of OCSs. Hence, OCSs have been used in carrier networks by operators with the strictest performance and reliability requirements for over a decade. Additionally, the base optical technologies, both MEMS and LCOS, have been widely deployed in carrier networks and have operated without fault for even longer. Stated another way, OCS is based on field-proven technology.
Whether used in a data center or to scale across data centers, an OCS offers several benefits that translate into lower costs over time.
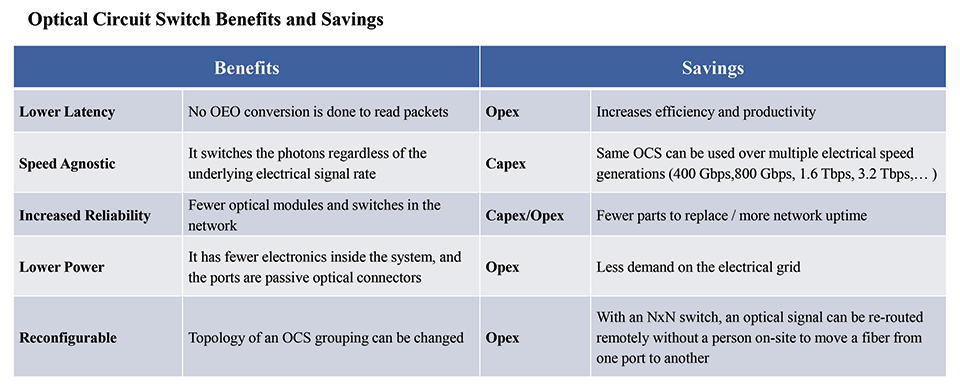
To address the specific needs for AI data centers, companies have launched new OCS products. The following is a list of the products available in the market:

Final Thought
AI infrastructure is diverging from conventional data center design at an unprecedented pace, and the networks connecting GPUs must evolve even faster than the GPUs themselves. OCS is not an exotic research architecture; it is a proven technology that is ready to be explored and considered for use in AI networks as a way to differentiate and evolve them to meet the stringent requirements of large AI clusters.