Last month was incredibly exciting, to say the least! We had the opportunity to attend two of the most impactful and prominent events in the industry: NVDA’s GTC followed by OFC.
As previously discussed in my pre-OFC show blog, we have been anticipating that AI networks will be in the spotlight at OFC 2024 and will accelerate the development of innovative optical connectivity solutions. These solutions are tailored to address the explosive growth in bandwidth within AI clusters while tackling cost and power consumption challenges. GTC 2024 has further intensified this focus. During GTC 2024, Nvidia announced the latest Blackwell B200 Tensor Core GPU, designed to empower trillion-parameter AI Large Language Models. The Blackwell B200 demands advanced 800 Gbps networking, aligning perfectly with the predictions outlined in our AI Networks for AI Workloads report. With an anticipated 10X traffic growth in AI workloads every two years, these AI workloads are expected to outpace traditional front-end networks by at least two speed upgrade cycles.
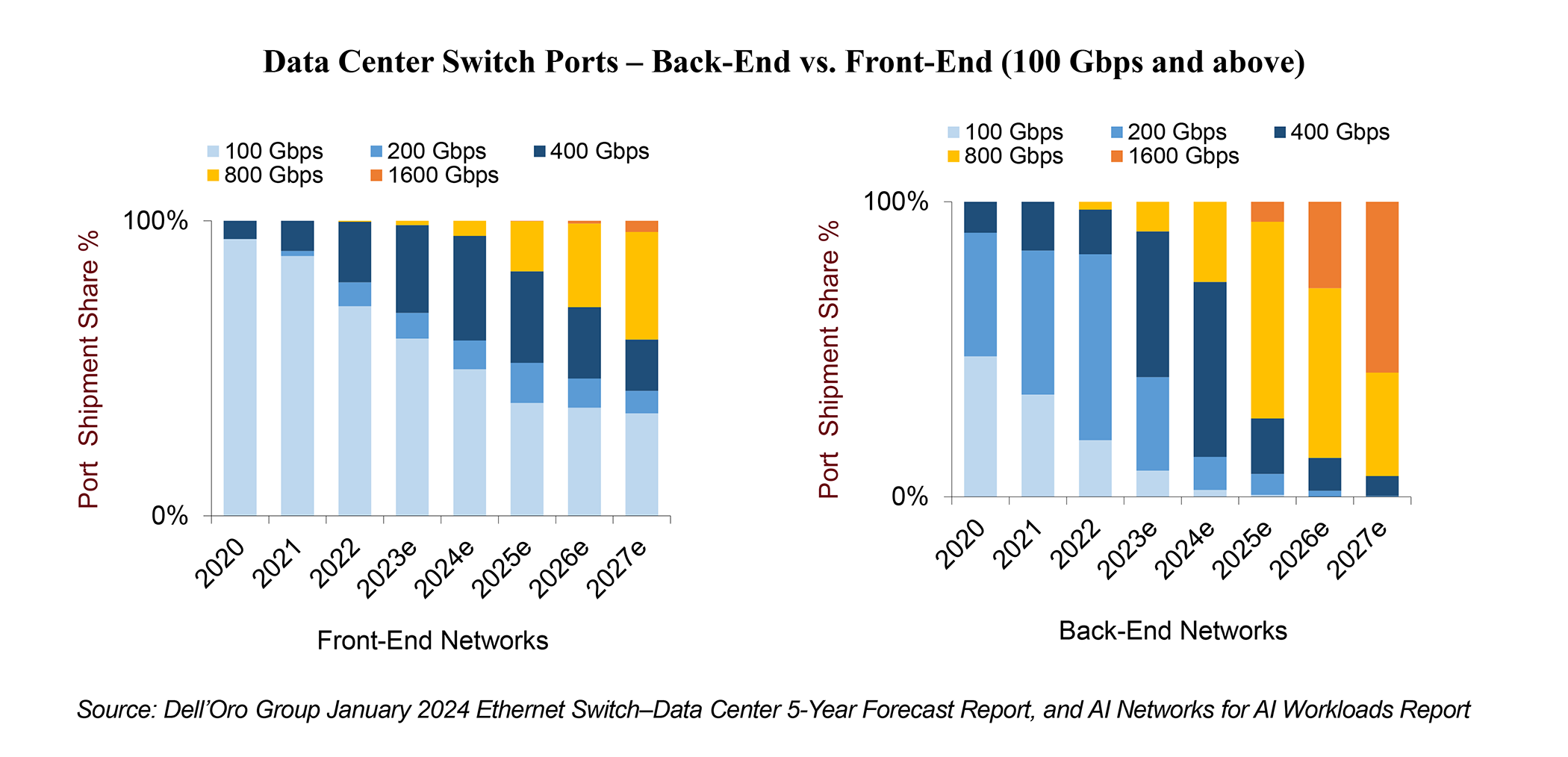
While a multitude of topics and innovative solutions were discussed at OFC regarding inter-data center applications as well as compute interconnect for scaling up the number of accelerators within the same domain, this blog will primarily focus on intra-data center applications. Specifically, it will focus on scaling out the network needed to connect various accelerated nodes in large AI clusters with 1000’s of accelerators. This network is commonly referred to in the industry as the ‘AI Back-end Network’ (also referred to; by some vendors; as the network for East-West traffic). Some of the topics and solutions that have been explored at the show are as follows:
1) Linear Drive Pluggable Optics vs. Linear Receive Optics vs. Co-Packaged Optics
Pluggable optics are expected to account for an increasingly significant portion of power consumption at a system level. An issue that will get further amplified as Cloud SPs build their next-generation AI networks featuring a proliferation of high-speed optics.
At OFC 2023, the introduction of Linear Drive Pluggable Optics (LPOs) promising significant cost and power savings through the removal of the DSP, initiated a flurry of testing activities. Fast forward to OFC 2024, we witnessed nearly 20 demonstrations, featuring key players including Amphenol, Eoptolink, HiSense, Innolight, and others. Conversations during the event revealed industry-wide enthusiasm for the high-quality 100G SerDes integrated into the latest 51.2 Tbps network switch chips, with many eager to capitalize on this advancement to be able to remove the DSP from the optical pluggable modules.
However, despite the excitement, the hesitancy from hyperscalers — with the exception of ByteDance and Tencent, who have announced plans to test the technology by end of this year— suggests that LPOs may not be poised for mass adoption just yet. Interviews highlighted hyperscalers’ reluctance to shoulder the responsibility of qualification and potential failure of LPOs. Instead, they express a preference for switch suppliers to handle those responsibilities.
In the interim, early deployments of 51.2 Tbps network chips are expected to continue leveraging pluggable optics, at least through the middle of next year. However, if LPOs can demonstrate safe deployment at mass scale while offering significant power savings for hyperscalers — enabling them to deploy more accelerators per rack — the temptation to adopt may prove irresistible. Ultimately, the decision hinges on whether LPOs can deliver on these promises.
Furthermore, Half-Retimed Linear Optics (HALO), also known as Linear Receive Optics (LROs) were discussed at the show. LRO integrates the DSP chip only on the transmitter side (as opposed to completely removing it in the case of LPOs). Our interviews revealed that while LPOs may proof to be doable at 100G-PAM4 SerDes, they may become challenging at 200G-PAM4 SerDes and that’s when LROs may be needed.
Meanwhile, Co-Packaged Optics (CPOs) remain in development, with large industry players such as Broadcom showcasing ongoing development and progress in the technology. While we believe current LPO and LRO solutions will certainly have a faster time to market with similar promises as CPOs, the latter may eventually become the sole solution capable of enabling higher speeds at some point in the future.
Before closing this section, let’s just not forget that, when possible, copper would be a much better alternative than all of the optical connectivity options discussed above. Put simply, use copper when you can, use optics when you must. Interestingly, liquid cooling may facilitate the densification of accelerators within the rack, enabling increased usage of copper for connecting various accelerator nodes within the same rack. The recent announcement of the NVIDIA GB200 NVL72 at GTC perfectly illustrates this trend.
2) Optical Circuit Switches
OFC 2024 brought some interesting Optical Circuit Switches (OCS) related announcements. OCS can bring many benefits including high bandwidth and low network latency as well as significant capex savings. That is because OCS switches can lead to a significant reduction in the number of required electrical switches within the network which eliminates the expensive optical-to-electrical-to-optical conversions associated with electrical switches. Additionally, unlike electrical switches, OCS switches are speed agnostic and don’t necessarily need to be upgraded when servers adopt next generation optical transceivers.
However, OCS is a novel technology and so far, only Google, after many years in development, was able to deploy it in mass in its data center networks. Additionally, OCS switches may require a change in the installed base of fiber. For that reason, we are still watching to see if any other Cloud SP, besides Google, has any plans to follow suit and adopt OCS switches in the network.
3) The Path to 3.2 Tbps
At OFC 2023, numerous 1.6 Tbps optical components and transceivers based on 200G per lambda were introduced. At OFC 2024, we witnessed further technology demonstrations of such 1.6 Tbps optics. While we don’t anticipate volume shipment of 1.6 Tbps until 2025/2026, the industry has already begun efforts in exploring various paths and options towards achieving 3.2 Tbps.
Given the complexity encountered in transitioning from 100G-PAM4 electrical lane speeds to 200G-PAM4, initial 3.2 Tbps solutions may utilize 16 lanes of 200G-PAM4 within an OSFP-XD form factor, instead of 8 lanes of 400G-PAMx. It’s worth noting that OSFP-XD, which was initially explored and demonstrated two years ago at OFC 2022, may be brought back to action due to the urgency stemming from AI cluster deployments. 3.2 Tbps solutions in OSFP-XD form factor offer superior faceplate density and cost savings compared to 1.6 Tbps. Ultimately, the industry is expected to figure out a way to enable 3.2 Tbps based on 8 lanes of 400G-PAMx SerDes, albeit it may take some time to reach that target.
In summary, OFC 2024 showcased numerous potential solutions aimed at addressing common challenges: cost, power, and speed. We anticipate that different hyperscalers will make distinct choices, leading to market diversification. However, one of the key considerations will be time to market. It’s important to note that the refresh cycle in the AI back-end network is typically around 18 to 24 months, significantly shorter compared to the 5 to 6 years seen in the traditional front-end networks used to connect general-purpose server.
For more detailed views and insights on the Ethernet Switch—Data Center report or the AI Networks for AI Workloads report, please contact us at dgsales@delloro.com.