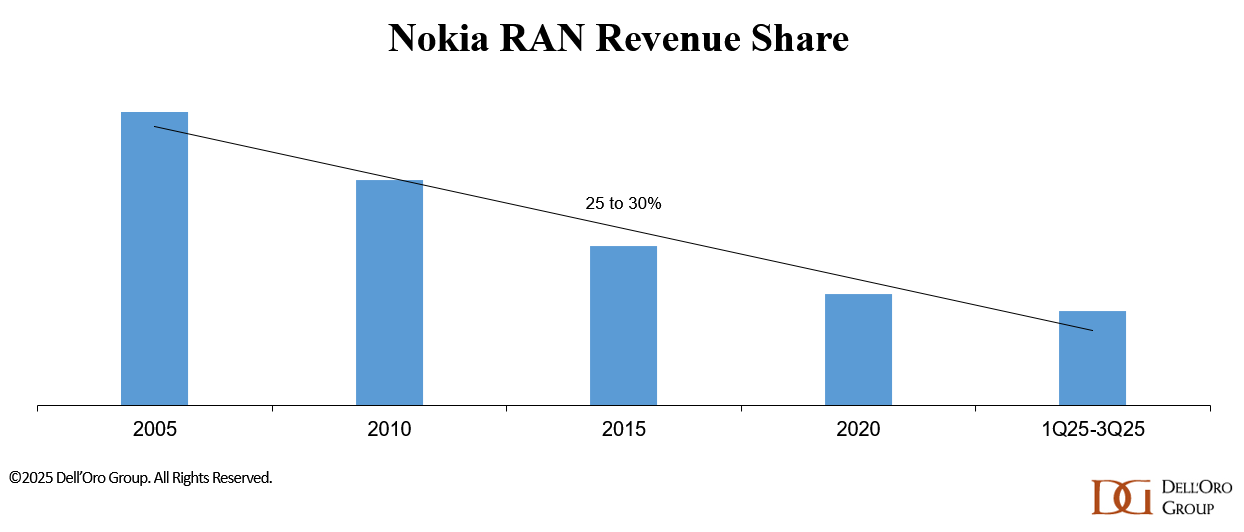
Nokia has a plan to reverse its declining RAN revenue share trajectory—and NVIDIA is now a significant part of that plan. What does this mean for the RAN market? After an intense month of updates from GTC and Nokia’s CMD, this is an opportune moment to review the scope of the Nokia–NVIDIA announcements, the potential RAN implications of their partnership, and Nokia’s broader RAN strategy.
A quick recap of NVIDIA’s entry into RAN: Based on the announcement and subsequent discussions, our understanding is that NVIDIA will invest $1 B in Nokia and that NVIDIA-powered AI-RAN products will be incorporated into Nokia’s RAN portfolio starting in 2027 (with trials beginning in 2026). While RAN compute—which represents less than half of the $30 B+ RAN market—is immaterial relative to NVIDIA’s $4+ T market cap, the potential upside becomes more meaningful when viewed in the context of NVIDIA’s broader telecom ambitions and its $165 B in trailing-twelve-month revenue.

Perhaps more importantly, both Nokia and NVIDIA appear aligned on the role that telecom networks and assets will play as we move deeper into the AI era. Both companies broadly believe that AI will transform society—enabling robots, self-driving cars, humanoids, and digital twins for manufacturing, among other use cases. NVIDIA envisions a future in which everything that moves will be autonomous. But achieving this requires transforming the network from a simple connectivity pipe into a distributed computing platform that functions as an AI grid.
Since this is not NVIDIA’s first attempt to enter the RAN market, it is worth noting that a key difference from prior efforts is a more pragmatic approach. Nokia is acutely aware of its customers’ risk profiles—operators cannot justify ROI based on unknowns. This time, the target is parity with its existing RAN in terms of performance, power, and TCO. Multi-tenancy and potential new revenue streams are certainly attractive, but they are not prerequisites—the ROI must stand on its own on a RAN-only basis.
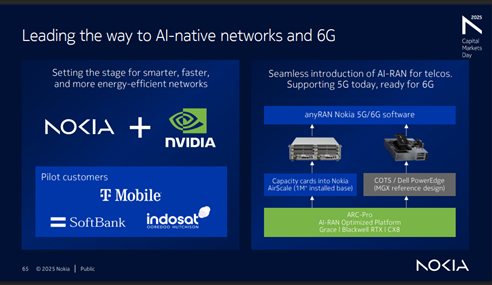
Given the size of Nokia’s 1 M+ BTS installed base, there are currently three high-level paths to transition towards NVIDIA’s GPU/AI-RAN, listed here in order of importance/projected shares: 1) Purpose-built D-RAN (add card into existing AirScale slots), 2) D-RAN vRAN (COTS at cell site), 3) C-RAN vRAN (centralized COTS).
Considering that the macro-RAN market—including both baseband and radio—totals around $30 B annually and suppliers ship 1–2 M macros per year, it is clear that carriers have limited appetite to spend $10+ K on a GPU, even if the software model could yield additional benefits over time. NVIDIA and Nokia will likely provide more details on performance and hopefully pricing soon. For now, NVIDIA has indicated that the GPU optimized for D-RAN will be priced similarly to the ARC-Compact, while delivering roughly twice the capacity. Nokia, meanwhile, is targeting further margin improvement; during its CMD, the company stated that the new Mobile Infrastructure BU is aiming for a 48%–50% gross margin by 2028, up from 48% for the 4Q24–3Q25 period.
If the TCO and performance-per-watt gap with custom silicon continues to narrow, this partnership could have meaningful implications across multiple RAN domains. Beyond strengthening Nokia’s financial position, it also provides momentum for both the AI-RAN and Cloud-RAN movements. While the AI-RAN train had already left the station—and was expected to scale significantly in the second half of the 5G cycle, propelling AI-RAN to account for around a third of RAN by 2029, even before this announcement—Nokia’s decision to lean further into GPUs will only reinforce this trend.
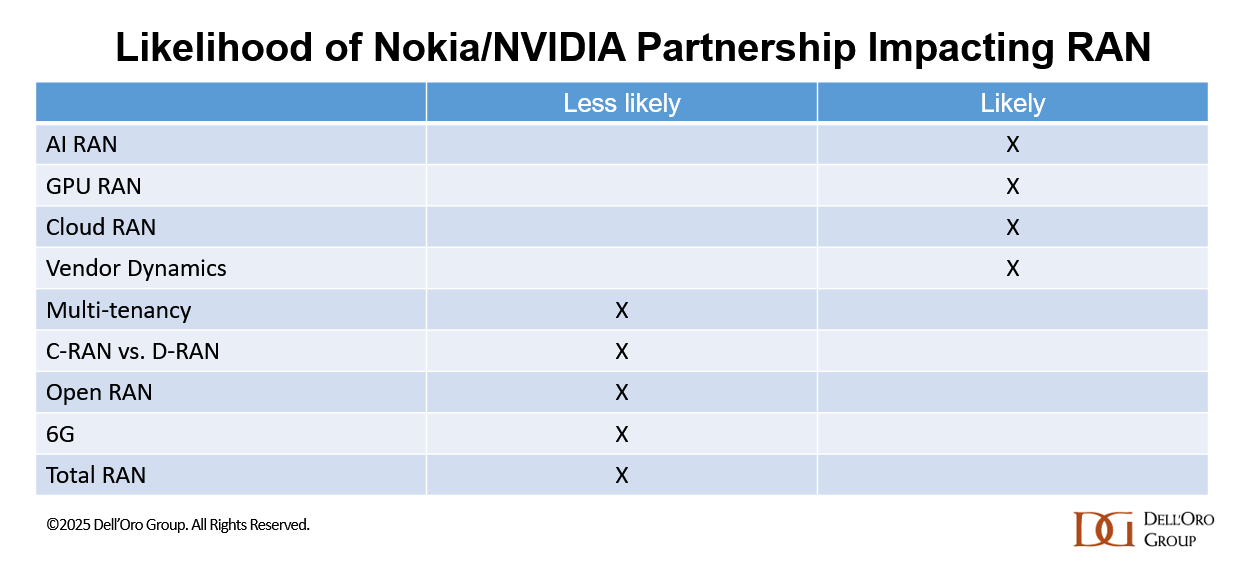
Since Nokia’s customers want to leverage their existing AirScale investments, the D-RAN option using empty AirScale slots is expected to dominate in the near term. At the same time, this partnership is unlikely to materially affect the C-RAN vs. D-RAN mix, Open RAN adoption, or the growth prospects for multi-tenancy RAN. The shift toward GPUs is also unlikely to alter the broader 6G trajectory.
However, it could influence vendor dynamics. Nokia remains optimistic that it can reverse its RAN share trajectory, which had been trending downward over an extended period until recently. During its November 2025 CMD, the company outlined plans to stabilize its RAN business in the near term and position itself for long-term growth. As we have highlighted in our quarterly RAN coverage, the market is becoming increasingly concentrated and polarized, and vendors must determine how best to maximize their chances of winning while navigating the inherent trade-offs (the top five suppliers accounted for 96% of the 1Q25-3Q25 RAN market).
Rather than chasing volume in markets that are open to all suppliers, Nokia plans to remain disciplined and focus on areas where it can differentiate and unlock value—particularly through software/faster innovation cycles via its recently announced partnership with NVIDIA. The company sees meaningful opportunities to capture incremental share in North America, Europe, India, and select APAC markets. And it is already off to a solid start— we estimate that Nokia’s 1Q25–3Q25 RAN revenue share outside North America improved slightly relative to 2024. Following this stabilization phase, Nokia is betting that its investments will pay off and that it will be well-positioned to lead with AI-native networks and 6G.
In other words, the objective is stability in the near term and growth over the long term. It is now up to Nokia and NVIDIA to execute.