Industrial giants are reshaping their portfolios at speed. Some are shedding non-core businesses to become focused pure-plays. Others are buying their way deeper into the data center. Both moves answer the same call: the AI buildout has become the industrial economy’s defining megatrend—and capital markets reward those who focus.
The End of the Everything Company
For most of the last century, scale and breadth were the point. General Electric was the template: jet engines, light bulbs, locomotives, medical scanners, home appliances, and a vast finance arm—all under one roof. Diversification was designed to smooth the cycle and compound the advantage.
Then investors stopped buying it. The complexity of these sprawling portfolios made them opaque to value and unwieldy to run. As a result, the market started applying a conglomerate discount, pricing the whole below the sum of its parts. A focused operator commands a higher multiple than the same business buried inside a diversified holding company. Breadth, in other words, was leaving money on the table.
GE eventually drew the obvious conclusion and broke itself into three: GE HealthCare, GE Vernova, and GE Aerospace. The logic now echoes across the industrial landscape. Honeywell is splitting into separate aerospace and automation companies while spinning off its advanced materials business into a new company, Solstice. United Technologies had beaten them to it back in 2020, separating into Carrier, Otis, and Raytheon.
Carrier’s Performing-While-Transforming Act
Carrier, born from that breakup, wasted little time before going further. Few companies have rebuilt themselves as aggressively. The throughline is simple: double down on intelligent climate and energy, exit everything else.
On the buy side, Carrier acquired Viessmann Climate Solutions, the German heating and heat-pump champion, for roughly €12 billion, with the deal closing in January 2024. It was a clear bet on the electrification of heat and on Carrier’s European core.
The sell side was busier. In a tightly choreographed portfolio transformation, Carrier shed the businesses that no longer fit. It sold Global Access Solutions, its security arm with the LenelS2, Supra, and Onity brands, to Honeywell for an enterprise value of $4.95 billion, around 17x EBITDA. Next came Industrial Fire and its Det-Tronics, Marioff, Autronica, and Fireye brands, sold to Sentinel Capital Partners for $1.425 billion. Soon it was Commercial Refrigeration’s turn, going to Haier for $775 million. And it capped the program by selling its Commercial and Residential Fire business to an affiliate of Lone Star Funds for $3 billion. An earlier exit, the sale of Chubb fire and security to APi Group, had already set the tone in 2021.
This is harder than a slide deck makes it look. Each carve-out means separating shared systems, renegotiating supplier contracts, staffing data rooms, and absorbing restructuring charges. All while hitting quarterly numbers and paying down the debt taken on for Viessmann. Carrier’s own framing, “performing while transforming,” was less a slogan than a description of the grind. CEO David Gitlin has noted that the divestitures were all signed within about a year of announcement, for a combined value of over $10 billion at a mid-teens EBITDA multiple in aggregate. The reward for the pain is a cleaner story and, the company is betting, a better multiple.
Johnson Controls Goes Pure-Play
A parallel story is playing out at Johnson Controls, a leader in data center thermal management. In August 2025, JCI completed the sale of its Residential and Light Commercial HVAC business to Bosch for $8.1 billion, including its residential joint venture with Hitachi. The move leaves JCI as a pure-play provider of building solutions, with around $5 billion in net proceeds and a $5 billion accelerated buyback.
The Bosch deal is the latest chapter in a long unwinding. JCI spun off its automotive seating business, Adient, back in 2016, then sold its lead-acid battery business, now Clarios, in 2019. Each step steered the company toward commercial buildings, and increasingly toward the data center. While paring the edges, JCI has reinforced the center, picking up hyperscale cooling specialist Silent-Aire and, more recently, direct-to-chip components maker Alloy Enterprises. The portfolio is getting narrower and deeper at the same time.
Trim Cooling to the Core
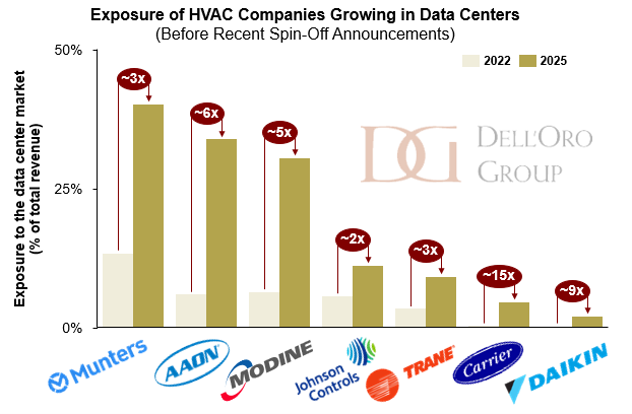
The pattern is spreading to HVAC players with one foot in other industries, which are now sharpening their focus on thermal and the data center.
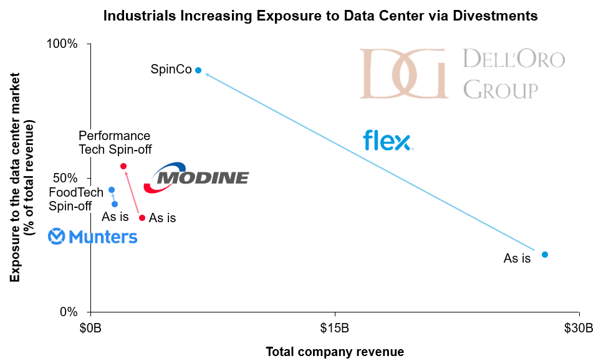
Modine offers a clean example. In January 2026, it agreed to spin off its Performance Technologies business and combine it with Gentherm, in a Reverse Morris Trust. Performance Technologies, the company’s vehicular and power-generation thermal arm, carries about $1.1 billion in revenue. The transaction is valued at roughly $1.0 billion, around 6.8x post-synergy EBITDA, with Modine taking a $210 million cash distribution and its shareholders ending up with about 40% of the combined company. What Modine keeps is the prize: its Climate Solutions segment, now a pure-play built around data center cooling and commercial HVAC. Management expects that business to keep compounding, with data center demand growing well into the double digits. Modine has fed it through acquisitions, too, from Airedale to Scott Springfield and the TMGcore immersion assets.
Munters is running a similar play. The Swedish climate specialist has organized itself around three segments, AirTech, FoodTech, and a fast-growing Data Center Technologies unit that now drives close to 40% of sales. Sharpening that focus, Munters has moved to offload its FoodTech business while continuing to build on the data center side, where its 2024 acquisition of chiller maker Geoclima added liquid-cooling and heat-rejection capacity. The direction of travel is unmistakable: less food and agriculture, more AI factory.
These portfolio moves are part of a wider wave. Many of these companies had already been steadily increasing their data center exposure for years before any spin-off; the breakups and divestitures only accelerate a shift that was well under way.
Crossing Over to the Electrical Side
The same realignment is reshaping the power half of the stack, and the marquee move belongs to Flex.
In May 2026, Flex announced it would spin off its Cloud and Power Infrastructure segment into a new, independent public company, provisionally called SpinCo. The new entity will be a grid-to-chip play, integrating power distribution, thermal management, and full infrastructure systems for AI data centers and mission-critical applications. The growth profile is the headline: Flex is targeting 65% to 75% revenue growth for the new company in fiscal 2027, accelerating beyond 80% the year after. Current Flex CEO Revathi Advaithi will lead SpinCo, signaling where the company sees its future. The remaining Flex stays an advanced manufacturing partner, and the split is expected to close in early 2027.
What makes the Flex story instructive is how the segment was built. Flex assembled it through M&A, adding critical-power specialist Anord Mardix, switchgear maker Crown Technical Systems, and direct-to-chip cooling startup JetCool. Buy the pieces, build the platform, then spin it out to let the market value it on its own terms. It is the conglomerate discount thesis run in reverse.
Flex is not alone on the electrical side. GE’s split produced GE Vernova, a pure-play power and grid company. ABB agreed to hand its robotics division to SoftBank for $5.375 billion. nVent sold its thermal management business, the RAYCHEM and TRACER heat-tracing brands, to Brookfield for $1.7 billion, to concentrate on electrical connection and protection.
No name, however, captures the realignment better than Eaton, which is also off-loading non-core assets. On June 2026, it agreed to separate its Mobility Group and combine it with Dana in a Reverse Morris Trust, valuing the vehicular business at about $5.1 billion and leaving Eaton shareholders with just over half of the combined company plus a $1.1 billion cash distribution. The spin-off sharpens its focus on electrical power.
But Eaton is not only shedding to refocus. It is also expanding inorganically. It added modular enclosure maker Fibrebond for $1.45 billion and solid-state transformer expertise through Resilient Power, building on earlier deals like Tripp Lite. The capstone is its $9.5 billion acquisition of Boyd Thermal, which vaults Eaton into liquid cooling at scale across CDUs, cold plates, and semiconductor thermal interface materials (TIMs), with the company guiding to roughly $1.5 billion in liquid-cooling revenue for 2026. With that cooling portfolio added to its electrical base, Eaton joins the ranks of vendors offering a full data center infrastructure stack.
The Full Stackers Get Fuller
While thermal and electrical specialists have reshaped their portfolios to raise their exposure to markets anchored in lasting high-growth fundamentals, the full stackers never had to. Already at the center of the digital infrastructure buildout, they have marched in a single direction: more power, more cooling, more of the stack.
Vertiv has been the most active. It strengthened white-space rack architectures by acquiring Great Lakes Data Racks & Cabinets for $200 million, around 11.5x EBITDA. It expanded its heat rejection and dry cooling offering with ThermoKey of Italy, adding EMEA manufacturing. And it reached up the thermal chain to the cold plate with Strategic Thermal Labs, adding server-side liquid-cooling design and validation. These sit alongside earlier moves into liquid cooling with CoolTera, into in-building power with E&I Engineering, and into commissioning and flushing services with PurgeRite. The strategy is end-to-end, grid-to-chip and across the lifecycle.
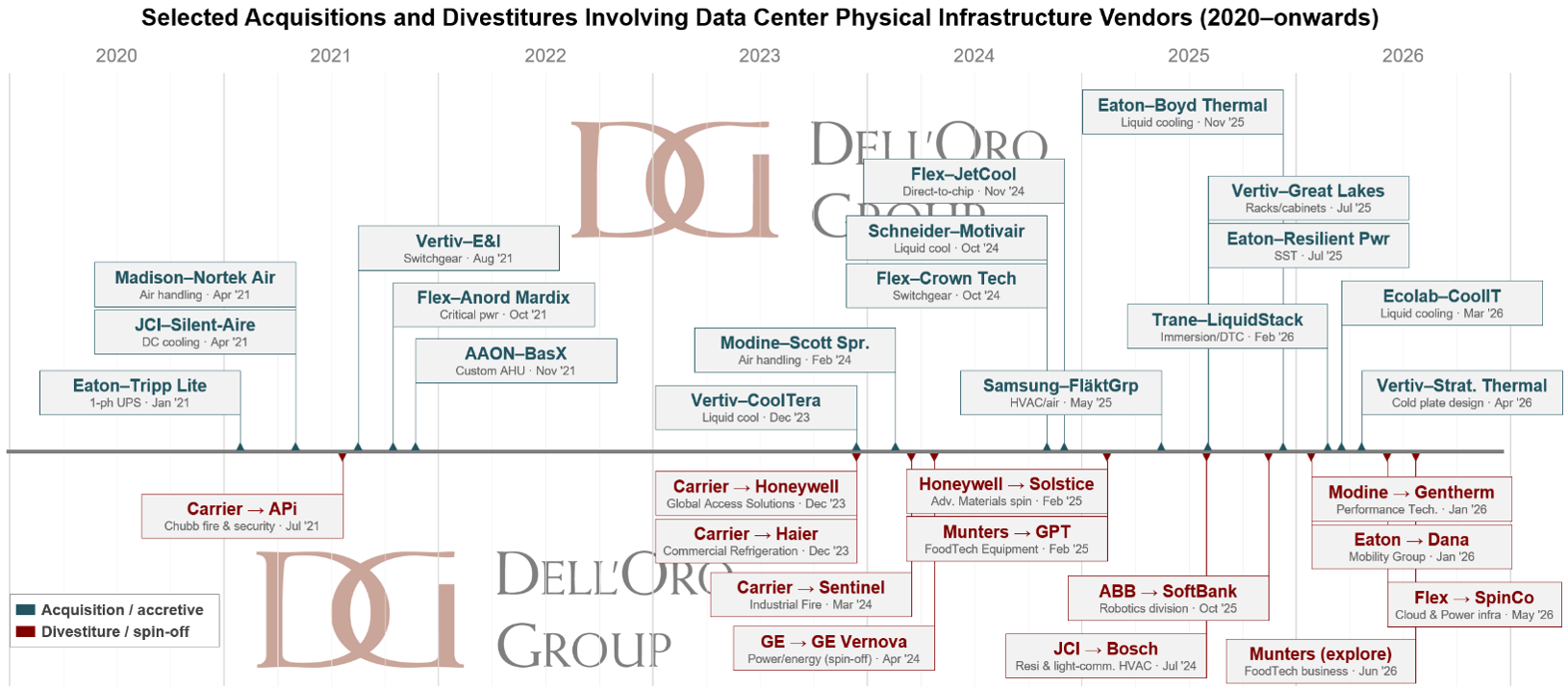
Schneider Electric has moved more selectively, favoring fewer but larger, high-conviction bets. In July 2025, it agreed to buy out Temasek’s remaining 35% stake in Schneider Electric India for €5.5 billion in cash, taking full ownership of one of its largest and fastest-growing markets. In cooling, it anchored its grid-to-chip ambitions with a 75% controlling stake in Motivair for $850 million. Motivair brings CDUs, cold plates, rear-door heat exchangers, and chillers, slotting directly into a portfolio that already spans power distribution and white space.
What unites them is a bet on breadth. Each is wagering that owning more of the stack will pay off, either by bundling additional products into the same deployment or by charging for the value of a coordinated, end-to-end design. The attach rate is never complete, and no vendor lands every power and thermal element in every project. But even a partial bundle, sold on the strength of a full-stack portfolio, can beat a point product standing alone.
New Entrants, Deep Pockets
If the incumbents are betting on breadth, another group is making a simpler bet: getting in at all. The most telling signal of this cycle is who is now arriving from outside the traditional infrastructure tent.
Ecolab, the water and hygiene giant, is the standout, and its move builds on a foundation laid years ago. Nalco Water, the treatment business it formed through the 2011 acquisition of Nalco for roughly $5.4 billion, already manages the cooling water that keeps data centers running. Moving from the facility loop to the fluid that cools the chip is the logical next step, and Ecolab took it by agreeing to acquire pure-play liquid-cooling specialist CoolIT Systems for $4.75 billion—a price 17 times what KKR and Mubadala paid only three years before. The premium is striking, but the opportunity behind it may be bigger still. As operators push warmer water through the technology cooling system (TCS) to chase efficiency, keeping that fluid clean and stable becomes a growing pain point, and few can answer it as completely as Ecolab, pairing CoolIT’s hardware with Nalco’s chemistry and the service to maintain both.
Others are crossing the same threshold. Samsung Electronics bought one of Europe’s largest HVAC makers, FläktGroup, for around €1.5 billion, planting a flag in data center precision cooling. Trane Technologies has built an end-to-end thermal stack with liquid cooling specialist LiquidStack and integrator Stellar Energy. Daikin Applied has reached into negative-pressure CDUs with Chilldyne and ultra-high-density cabinets with DDC Solutions. And on the electrical side, Legrand has run a near-continuous bolt-on campaign across busbars, racks, and power distribution, turning a steady stream of small deals into a serious data center franchise.
The New Megatrend
M&A in this sector is running hot, and there is little reason for it to cool down. We flagged as much in our 2026 predictions, where we expect still more deals to cross the $1 billion mark this year. As long as data center capex hovers around a trillion dollars, the business case for acquiring technical capability, manufacturing capacity, and customer relationships writes itself. No activist investor complains that a vendor is too exposed to the data center.
In an era of market exuberance, what makes this moment striking is the discipline. With capital abundant and investor appetite insatiable, an AI label on almost any acquisition would win expedited board approval. Yet the leading industrials are doing the opposite. Like a gardener pruning back the branches of a tree so it bears more succulent fruit, CEOs are reshaping the business for the AI age: offloading distraction, sharpening focus.
This is one of the AI buildout’s more unintended consequences. Industrial stocks have been among the market’s strongest performers in recent years. But the surging demand for electrical and mechanical equipment lifting their shares is only half the story. The bigger story is how AI is pushing these companies to remake themselves from within, unsettling the entire industrial ecosystem.
Industrial vendors have often coalesced around megatrends. For the past two decades, decarbonization and electrification set the agenda and shaped where capital flowed. Now, the AI buildout, and the next industrial revolution expected to ensue, is the dominant force—and the figures show how keen the industrials are to raise their exposure to it.
Are these industrial powerhouses making a mistake by tuning their portfolios to the AI buildout, or are they building a durable, long-term value-creation machine? Only time will tell. But unlike the software and internet companies that torched capital through the dot-com bubble, the industrials are taking a measured approach. And as they transform, they are emerging stronger, with leaner, more innovative portfolios better positioned to capture the opportunities that lie ahead.
###
| This blog post shows only a reduced set of the data points behind our analysis. For deeper analysis with full charts, access our client-only version at Dell’Oro Client Portal or reach out to the Sales team to learn about becoming a subscriber. |