As 6G discussions continue to evolve, the industry conversation is becoming more pragmatic. Compared to the early phase of 5G, there is less emphasis on transformational narratives and more on deployment realities, efficiency gains, and economics, with a better balance between what we know and what we don’t know. That does not mean 6G lacks ambition. However, some aspects of 6G RAN are increasingly likely, while others remain far less certain.

The Baseline Deployment Model Appears Increasingly Evolutionary
The baseline 6G deployment model increasingly appears evolutionary rather than revolutionary. Wide-area deployments will likely continue to rely on Massive MIMO macro infrastructure using large contiguous spectrum blocks below 8.4 GHz. While higher-frequency bands and more advanced spectrum layers will remain important in specific use cases, the baseline scenario is that operators will prioritize practical coverage economics, infrastructure reuse, and deployment efficiency. Similar to 5G, small cells will remain important for densification and indoor coverage, though early deployments will likely focus on outdoor macro layers.
AI and 6G should improve efficiency, though gains will likely remain in the 10% to 50% range. Since the RAN accounts for less than 15% of the overall wireless capex and recurring site opex over the life of the cell site, the economics fall apart if a significant number of new sites are needed to realize equivalent coverage. As a result, wider-spectrum channels using the existing macro grid will remain the primary mechanism for expanding capacity and lowering cost per bit in 6G.
Economics is driven by The Knowns
One of the more important shifts from 5G to 6G may ultimately be the investment logic itself. Both 4G and 5G were technical successes, particularly 5G, which delivered a massive capacity increase. But from a commercial perspective, the 1% CAGR over the past 15 years supports the premise that these technologies did little to reverse the flattish trajectory of operator revenue.
During the early 5G cycle, many operators emphasized new revenue streams driven by broader enterprise adoption and advanced 5G features tied to emerging applications. In contrast, early 6G discussions appear significantly more focused on efficiency, automation, and improving network economics. Suppliers and operators focus more on what they can control and what they know.
Lower cost-per-bit, efficiency gains, and platform modernization increasingly form the core justification for 6G investment. New services and revenue streams will still matter, especially as data traffic growth rates are moderating. However, operators are less likely to rely on uncertain future monetization assumptions as the primary basis for large-scale investment decisions.
AI-Native RAN Is Likely to Become Foundational
One area where industry alignment is becoming increasingly clear is AI-native RAN. Unlike previous generations, where AI was largely introduced as an add-on after the initial deployments, 6G is expected to incorporate AI capabilities into the RAN architecture from the start. And it is not just the baseband—suppliers are now bringing intelligence into every RAN layer, including the radios. Ericsson’s launch of ten AI-ready radios featuring in-house silicon with neural network accelerators is a case in point.
The implementation models remain difficult to predict. Today, most AI RAN activity centers on distributed AI-for-RAN solutions designed to improve performance and efficiency while leveraging existing 5G infrastructure. Current industry consensus also suggests non-GPU RAN will dominate 6G AI RAN deployments, reflecting infrastructure reuse, cell-site constraints, and multi-purpose tenancy requirements.
Setting aside what is underneath the hood, the broader direction is becoming clearer: AI RAN is evolving from an optional enhancement to a foundational element of the 6G architecture.
Open Fronthaul Will Continue to Expand
The Open RAN discussion is also evolving. Openness, automation, virtualization, and AI integration remain central to next-generation RAN platforms, though adoption curves will vary. The earlier emphasis on openness as a multi-vendor strategy is gradually giving way to a stronger focus on programmability, automation, and software-centric operations. Open FH, RIC frameworks, and software-driven optimization are expected to support increasingly AI-native RAN architectures over time.
At the same time, broader adoption of Open FH does not necessarily imply widespread multi-vendor RAN deployments. Per our latest Open RAN report, 6G Open FH adoption is expected to be significant from the start, while Multi-vendor RAN is projected to account for less than 5 percent of total RAN by 2030.
OFDM-based 6G evolution
Based on current industry visibility, the most likely 6G waveform outcome is an evolutionary path built around enhanced OFDM rather than a completely new waveform. OFDM is not ideal for all applications, but it already underpins the global 4G and 5G ecosystem and remains highly compatible with massive MIMO, beamforming, flexible spectrum use, and existing silicon architectures.
Alternative waveform candidates such as OTFS continue to be evaluated for specific 6G use cases, including high mobility and integrated sensing and communications (ISAC). These opportunities remain small relative to the broader MBB market, and after balancing all the trade-offs, it appears that the alternative waveform has yet to demonstrate sufficient system-level benefits to justify replacing OFDM at scale.
The Upside with AI and New Use Cases remain Uncertain
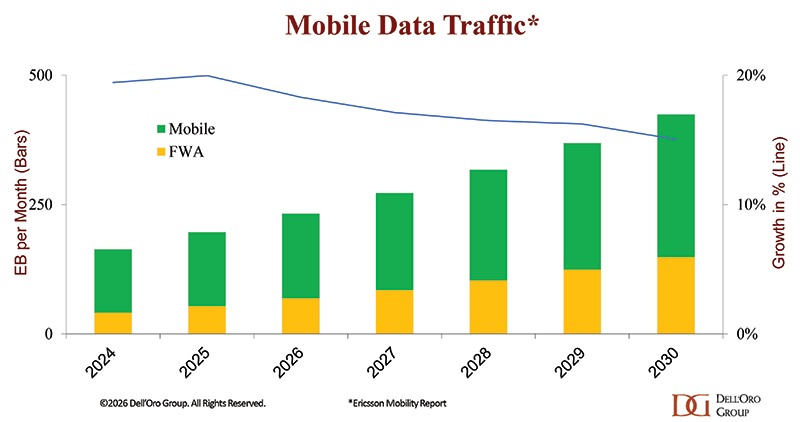
One of the biggest uncertainties remains the demand side of the equation. Baseline projections from Ericsson’s Mobility Report suggest total mobile network traffic, including mobile broadband and FWA, will grow 15% to 20% annually over the next five years. Importantly, these projections largely assume that usage patterns remain stable and are driven primarily by existing smartphone behavior and adoption trends.
If AI-native devices materially change how users interact with networks over the next decade, traffic patterns could shift significantly, especially if we move towards an environment in which more data is continuously recorded, analyzed, and uploaded throughout the day.
Beyond new MBB devices, the industry continues to discuss immersive applications, AI inference, industrial automation, digital twins, autonomous systems, and AI-driven services. However, visibility remains limited regarding which use cases will scale commercially, how quickly adoption will occur, and how dependent these applications will ultimately be on 6G-specific capabilities.
And while human consumption of video is inherently constrained, machine-generated traffic is not. In other words, the mobile broadband forecast tied to existing use cases is relatively clear. The outlook for new devices, new applications, and machine-driven traffic is far more uncertain.
ISAC Continues to Generate Significant Interest
ISAC remains one of the most active areas of 6G research and standardization discussion. The concept is compelling. Future RANs could potentially support both communications and environmental sensing capabilities simultaneously, enabling applications ranging from drone detection to vehicular awareness and industrial positioning.
Similar to FWA, the MBB business case can largely stand on its own, while ISAC upside remains incremental. One major difference is that ISAC will require more site modifications, and, as a result, operators need to understand where it makes sense to justify the incremental complexity inherent in ISAC.
ISAC may eventually become strategically important as the visibility improves, but it is clearly not yet the primary driver behind early 6G investment planning.
The Pace — and Depth — of 6G Adoption
A major uncertainty is not whether 6G will be deployed, but how aggressively operators will scale it over time. It also remains unclear how large the gap will become between early adopters and the late majority.
While early adopters in markets such as China, India, Japan, and Korea will likely move relatively quickly to establish initial 6G coverage layers, it remains unclear what the coverage ascent and capex envelope will look like compared with upper mid-band 5G rollouts. And more generally, the pace of network deepening after the initial rollout phase remains less clear.
Today, many operators emphasize that 6G will be more evolutionary than previous generational transitions, relying more on software and fewer large-scale hardware upgrades. In this view, 6G represents a more pragmatic, economically disciplined upgrade cycle with lower capex/revenue growth relative to previous technology cycles.
At the same time, history suggests competitive dynamics often evolve differently once deployment cycles begin. Operators frequently enter new technology generations that emphasize efficiency and disciplined capital allocation, only to gradually return to more traditional forms of network differentiation centered on coverage, performance, and capacity leadership.
As a result, the eventual 6G capex envelope — and the corresponding impact on industry capex intensity — remains difficult to predict.
Cloud RAN Adoption is Unclear
Visibility into emerging RAN segments/architectures varies significantly. The likelihood of mass adoption by 2030 is now assessed as very likely for 6G and AI RAN, less likely for Cloud RAN, and unlikely for multi-vendor RAN.
To clarify, the overarching belief is that all roads lead to more virtualization, especially with 6G. The Cloud RAN architecture is increasingly viewed as a foundational step in the automation journey. However, the pace and depth of Cloud RAN adoption remain less certain.
Since the primary metric is TCO, the performance-per-dollar-per-watt gap between custom silicon and COTS plus accelerators needs to narrow for operators to gradually increase the COTS share with 5G and achieve a significant shift with 6G.
Conclusion
The overall direction of 6G RAN is gradually becoming clearer, even if many important questions remain unresolved.
The strongest areas of industry alignment increasingly center on wide-area deployments, AI-native RAN, and practical investment economics. Visibility remains far less certain regarding new applications, sensing monetization, enterprise demand, AI’s impact on mobile data traffic, deployment pace, and the depth of Cloud RAN adoption.
It is easier to invest the minimum amount in what we know than to invest the right amount in what we don’t know.