At this year’s NVIDIA GTC, the narrative has moved decisively beyond the initial shift to accelerated computing. What stood out in 2026 is not just the continuation of that trend, but the expansion of AI infrastructure into a heterogeneous, domain-specific ecosystem.
As an analyst covering data center compute, the key takeaway is clear: the industry is entering its next phase—where optimization, not just scale, becomes the defining battleground.
From Retrieval to Generative—and Now to Reasoning Infrastructure
Hyperscaler workloads have evolved rapidly from retrieval-based systems toward generative AI, and now increasingly toward reasoning-driven architectures. Internal workloads such as search are being fundamentally re-architected around AI models, signaling a structural shift in how compute is deployed.
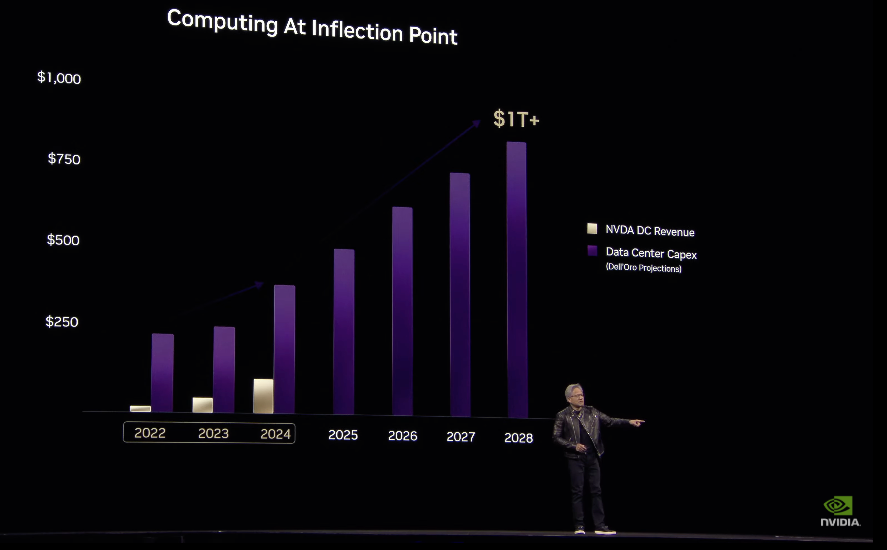
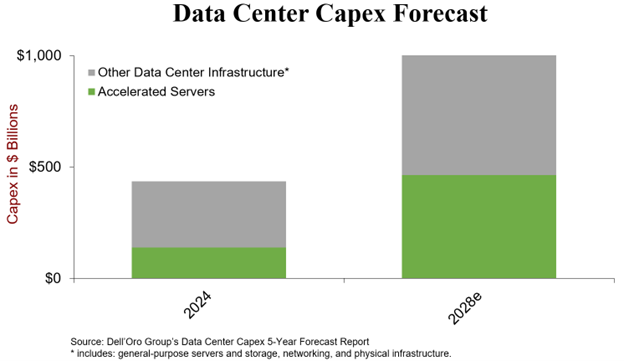
This transition continues to drive strong demand for accelerated computing. At Dell’Oro Group, we project global data center capex to exceed $1.7 T by 2030. These estimates could prove conservative given the scale of investment being signaled by hyperscalers, including multi-hundred-billion-dollar capex trajectories and long-term, large-scale infrastructure commitments.
The Emergence of LPUs: A Potential Inflection Point
LPUs, particularly through NVIDIA’s partnership with Groq, represent one of the more strategically important developments. Their SRAM-based architecture is optimized for low latency and strong performance per watt, enabling lower cost per token for inference and reasoning workloads.
This introduces greater flexibility in infrastructure design. Different service tiers can be optimized independently, with throughput-oriented configurations for lower-cost services and latency-sensitive deployments for premium offerings. LPUs provide a mechanism to fine-tune this balance in ways that GPUs alone cannot fully achieve.
Early deployments suggest LPUs can be configured at meaningful density. For example, a single Groq LPU rack can integrate hundreds of processors highlighting the degree of parallelism available for inference and reasoning workloads. In practice, such systems are likely to be deployed alongside GPU clusters, with the ratio depending on workload mix and service requirements.
If adoption reaches even modest levels, LPUs could expand the silicon TAM for domain-specific accelerators. At the same time, it remains unclear whether LPUs will primarily complement GPUs or displace portions of certain workloads as operators optimize for overall system efficiency. More broadly, LPUs underscore the growing importance of architectural specialization tailored to specific workload requirements.
GPU Roadmap: Density and Scale Continue to Accelerate
NVIDIA continues to push aggressively on GPU density and system integration. Platforms such as Vera Rubin Ultra demonstrate this trajectory, with multi-die architectures, massive HBM capacity reaching the terabyte scale per package, and highly dense, liquid-cooled rack designs.
Future platforms such as Feynman are expected to push these limits further, increasing both compute density and system complexity. However, this rapid scaling introduces new constraints around power, cooling, and system balance. As a result, complementary architectures and more specialized components will play a growing role in maintaining overall efficiency. With compute costs remaining elevated and data center capex scaling into the hundreds of billions annually, operators will need to strategically align infrastructure with domain-specific workloads to maximize efficiency and reduce total cost of ownership.
Interconnects: Balancing Standards and Proprietary Innovation
Interconnect strategy remains central to NVIDIA’s roadmap. The company continues to balance proprietary innovation with industry standards, investing in both InfiniBand and Ethernet for scale-out connectivity while advancing NVLink as the backbone of scale-up architectures.
As scale-up domains expand, NVLink will increasingly need to extend beyond the rack and, over time, into the optical domain. This evolution is necessary to support larger, more tightly coupled compute fabrics, but also introduces new technical challenges.
The expansion of scale-up capabilities naturally raises the question of whether they could displace portions of traditional scale-out networking. In practice, both architectures will need to evolve in parallel. Scale-up enables higher performance within tightly coupled systems, while scale-out remains essential for resilience, workload distribution, and efficient utilization across clusters. This is increasingly true not only for training but also for inference, where distributed workloads and service-level requirements demand flexibility.
NVIDIA is reducing reliance on PCIe-based x86 systems by positioning NVLink as an alternative interconnect. With initiatives such as NVLink Fusion and the development of its own CPU roadmap, the company is positioning NVLink as a broader system fabric that could extend beyond GPUs.
Connectivity, Networking, and System-Level Optimization
Connectivity is rapidly emerging as one of the primary constraints in next-generation AI infrastructure. Current systems are largely built on 200 Gbps SerDes, but the industry is already looking ahead to 400 Gbps SerDes. However, the transition to 400 Gbps presents significant challenges in signal integrity, power consumption, and packaging complexity, making the timeline aggressive and execution uncertain.
In this context, NVIDIA’s vertically integrated approach provides a meaningful advantage. Its control over InfiniBand technology, including SerDes development, allows it to move ahead of standard Ethernet ecosystems when necessary, particularly when industry standards lag behind system requirements.
At the same time, networking is no longer just about bandwidth. Smart NICs and DPUs, particularly NVIDIA’s BlueField platform, are becoming increasingly central to system architecture, with the market projected to grow at a 30% CAGR over the next five years. DPUs are expanding into broader roles within the AI infrastructure, managing data movement between compute, storage, and CPU domains while offloading networking and orchestration tasks from primary processors..
Taken together, these trends point toward a broader shift to system-level optimization, where performance is increasingly determined by how effectively compute, networking, and storage are integrated across the entire infrastructure stack.
Expanding the Platform: Beyond GPUs to Full-Stack Infrastructure
While GPUs remain the foundation of AI infrastructure, NVIDIA is clearly extending its reach across the full data center stack. Beyond its focus on domain-specific accelerators, GTC 2026 also highlighted the dense Vera CPU platform optimized for orchestrating agentic AI workloads, as well as the STX platform designed for KV cache-based context memory. A central theme underpinning this expansion is the increasing importance of co-design—bringing together compute, networking, and storage disciplines into a unified, system-level architecture rather than optimizing each component in isolation.
Taken together, these developments signal a clear expansion of NVIDIA’s total addressable market—from GPUs alone to a broader, full-stack infrastructure opportunity spanning compute, networking, and storage.
From Scale to Optimization: The Path Forward
NVIDIA’s rapid innovation cadence raises important questions around long-term economics, particularly as systems become more complex and capital-intensive. Maintaining a strong return on investment will depend not only on hardware performance, but on how effectively these systems can be utilized over time.
Here, NVIDIA’s software ecosystem remains a key advantage. CUDA provides continuity across generations, allowing developers to extract incremental performance improvements and enabling mixed-generation deployments that improve overall total cost of ownership.
More broadly, GTC 2026 makes it clear that the industry is moving beyond the initial phase of scaling AI infrastructure and into one defined by optimization and specialization. The shift toward heterogeneous architectures, combined with a growing focus on efficiency and workload-specific design, is reshaping how data centers are built and operated.