A few months after Upscale AI introduced SkyHammer—its clean-slate, open-standards scale-up platform designed to make XPUs “behave like a single coherent machine”—the firm is now extending its vision for open AI networking infrastructure into the scale-out domain, where clusters expand horizontally across multiple racks and, increasingly, across multiple data centers. To that end, Upscale AI is announcing a strategic partnership with NVIDIA aimed at accelerating the deployment of open, scale-out AI networking infrastructure for next-generation data centers.
The collaboration brings together NVIDIA’s Spectrum-X Ethernet switch silicon and Upscale AI’s AI-optimized, SONiC-based networking software to deliver interoperable, high-performance Ethernet fabrics designed for large-scale AI workloads.
As enterprises and neocloud providers expand AI clusters, networking has emerged as a critical bottleneck. The partnership focuses on enabling these customers to deploy scalable, low-latency networking systems that support heterogeneous environments spanning compute, accelerators, memory, and storage.
Open Infrastructure for Heterogeneous AI Environments
As part of the initiative, Upscale AI has joined the NVIDIA Partner Network. The partnership is intended to give customers greater flexibility in how they design and procure AI infrastructure, including deploying Ethernet switching powered by NVIDIA Spectrum silicon in heterogeneous, multi-vendor environments. This collaboration reflects a step toward more interoperable Ethernet infrastructure for AI deployments, while maintaining operational consistency at scale.
Focus on AI-Optimized SONiC
A core element of Upscale AI’s approach is its AI-optimized implementation of SONiC, the open-source network operating system widely used in hyperscale environments.
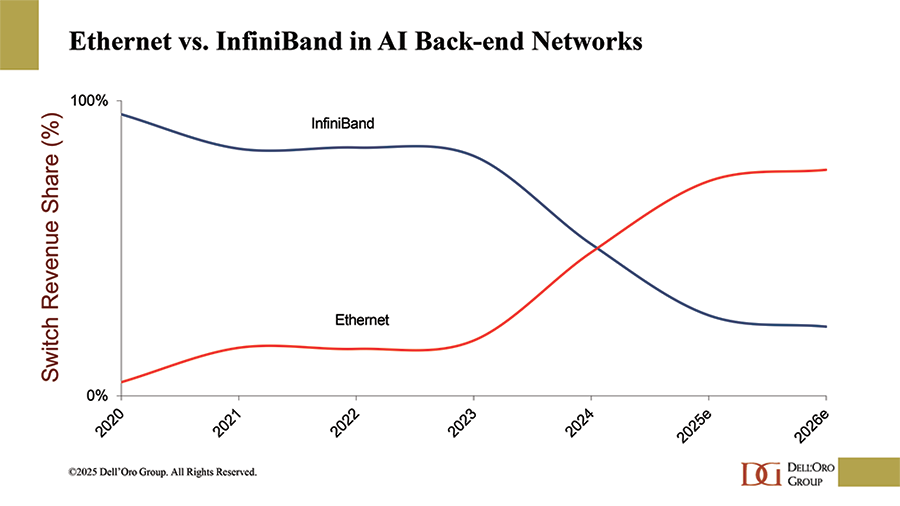
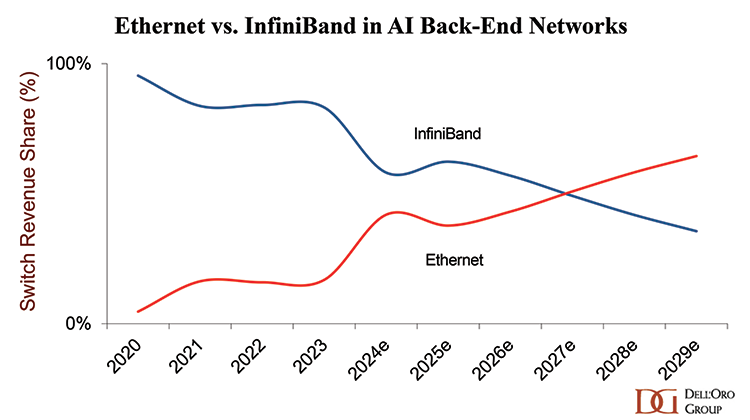
At Dell’Oro Group, we expect SONiC adoption in AI back-end networks to accelerate much faster than what we have historically observed in front-end networks. This faster uptake will be driven by several tailwinds on both the demand as well as supply sides.
On the demand side, a growing number of fast-growing AI model builders and neocloud providers are evaluating SONiC to diversify vendors, reduce platform lock-in, and gain greater control over their network infrastructure. Vendor diversification also helps mitigate risk especially as supply availability tightens.
On the supply side, an expanding ecosystem of established vendors and new entrants is supporting the SONiC ecosystem. We expect SONiC-based switch sales in AI scale-out networks to grow at more than 50 % CAGR (2025-2030), exceeding $10 B by 2030.

Addressing a Critical Gap with Fully Integrated AI Infrastructure for Enterprise and Neocloud Customers
Historically, SONiC adoption has been spearheaded by hyperscalers. However, deploying and operating an open-source network operating system like SONiC demands substantial in-house engineering expertise and integration effort—capabilities many smaller cloud providers and enterprises lack. In addition, SONiC broader ecosystem support—such as turnkey distributions, enterprise-grade tooling, and vendor-backed support—has lagged proprietary network operating systems offerings, limiting SONiC adoption beyond hyperscale environments.
Upscale AI plans to bridge this gap by delivering fully integrated solutions that combine hardware, software, and lifecycle services targeted at organizations building medium and large-scale AI environments.
While the first wave of AI has been driven primarily by large AI model builders—namely hyperscalers—the second wave is expected to be led by other cloud providers, including neocloud providers, as well as large enterprises. Together, these customer segments are projected to account for the majority of the Ethernet data center switch sales in scale-out networks by 2030.

Stitching Together an Open Fabric for AI
SkyHammer was step one. Scale-out is step two. Upscale AI is stitching together an open networking story—from the scale-up interconnect that makes XPUs act like one system, to the Ethernet fabric that lets AI environments grow horizontally while preserving multi-vendor flexibility. The NVIDIA partnership helps validate that direction and accelerates the scale-out side of the roadmap, reinforcing Upscale AI’s broader goal: open, interoperable AI networking infrastructure from pod to cluster.