AI capacity announcements are multiplying fast—but many overlap, repeat, or overstate what will realistically be built. Untangling this spaghetti means understanding when multiple headlines point to the same capacity and recognizing that delivery timelines matter as much as the billions of dollars and gigawatts announced.
AI is often hailed as a force set to redefine productivity — yet, for now, it consumes much of our time simply trying to make sense of the scale and direction of AI investment activity. Every week brings record-breaking announcements: a new model surpassing benchmarks, another multi-gigawatt data center breaking ground, or one AI firm taking a stake in another. Each adds fuel to the frenzy, amplifying the exuberance that continues to ripple through equity markets.
When AI Announcements Become “Spaghetti”
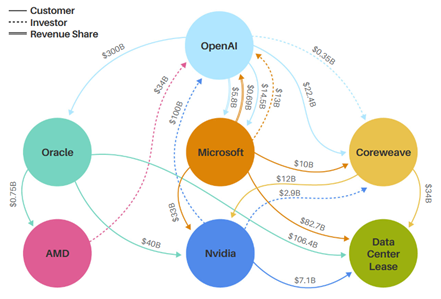
In recent weeks, the industry’s attention has zeroed in on the tangled web of AI cross‑investments, often visualized through “spaghetti charts.” NVIDIA has invested in its customer OpenAI, which, in turn, has taken a stake in AMD — a direct NVIDIA competitor — while also becoming one of AMD’s largest GPU customers. CoreWeave carries a significant investment from NVIDIA, while ranking among its top GPU buyers, and even leasing those same GPUs back to NVIDIA as one of its key compute suppliers. These overlapping stakes have raised questions about governance and prompted déjà vu comparisons with past bubbles. Morgan Stanley’s Todd Castagno captured this dynamic in his now‑famous spaghetti chart, featured in Barron’s and below, which quickly circulated among investors and analysts alike.
Why Venn Diagrams Matter More Than Spaghetti Charts
Yet while investors may have reason to worry about these tangled relationships, data center operators, vendors, and analysts should be paying attention to two other kinds of charts: Venn diagrams and Gantt charts.
In our conversations at Dell’Oro Group’s data center practice, we’re consistently asked: “How much of these announced gigawatts are double‑counted?” and “Can the industry realistically deliver all these GWs?” These are the right questions. For suppliers trying to plan capacity and for investors attempting to size the real opportunity, understanding overlap is far more important than tracking every new headline.
When all public announcements are tallied, the theoretical pipeline can easily stretch into the several‑hundred‑gigawatt range — far above what our models suggest will actually be built by 2029. This leads to the core issue: how do we make sense of all these overlapping (and at times even contradicting) announcements?
The OpenAI Example: One Company, Multiple Overlapping GW Claims
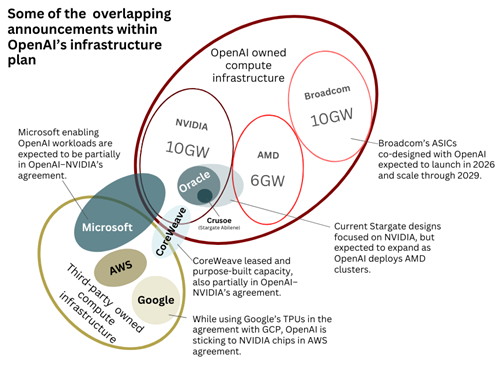
Consider OpenAI’s recent announcements. A longtime NVIDIA customer, the company committed to deploy 10 GW of NVIDIA systems, followed only weeks later by news of 6 GW of AMD‑based systems and 10 GW of custom accelerators developed with Broadcom. From a semiconductor standpoint, that totals roughly 26 GW of potential IT capacity.
On the data center construction side, however, the math becomes far less clear. OpenAI’s Stargate venture launched earlier this year with plans for 10 GW of capacity in the U.S. over four years — later expanded to include more sites and accelerated timelines.
Its flagship campus in Abilene, Tex. is part of Crusoe’s and Lancium’s Clean Campus development, expected to provide about 1.2 GW of that capacity. The initiative also includes multiple Oracle‑operated sites totaling around 5 GW (including the Crusoe-developed Abilene project, which Oracle will operate for OpenAI, and other sites developed with partners like Vantage Data Centers), plus at least 2 GW in leased capacity from neocloud provider CoreWeave. That leaves roughly 3 GW of U.S. capacity yet to be allocated to specific data center sites.
Assuming Stargate’s full 10 GW materializes domestically, OpenAI’s remaining 16 GW from its 26 GW of chip‑related announcements is still unallocated to specific data center projects. A portion of this may be absorbed by overseas Stargate offshoots in the U.A.E., Norway, and the U.K., generally developed with partners such as G42 and Nscale. These countries are already confirmed locations, but several additional European and Asian markets are widely rumored to be next in line for expansion.
Shared Sites, Shared Announcements, Shared Capacity
While OpenAI‑dedicated Stargate sites draw significant attention, the reality is that most of the remaining capacity likely ties back to Microsoft — the model builder’s largest compute partner and major shareholder. Microsoft’s new AI factories, including the Fairwater campus in Wisconsin, have been publicly described as shared infrastructure supporting both Microsoft’s own AI models and OpenAI’s workloads.
Naturally, Microsoft’s multibillion‑dollar capex program has come under close investor scrutiny. But to understand actual capacity expansion, one must ask: how much of this spend ultimately supports OpenAI? Whether through direct capital commitments or via absorbed costs within Azure‑hosted AI services, a meaningful share of Microsoft’s infrastructure buildout will inevitably carry OpenAI’s workloads forward.
Given the size and complexity of these projects, it’s unsurprising that multiple stakeholders — chipmakers, cloud providers, developers, utilities, and investors — announce capacity expansions tied to the same underlying sites.
A clear example is Stargate UAE, which has been unveiled from multiple angles:
- OpenAI publicized the collaboration;
- G42 highlighted its development role;
- Khazna detailed its responsibility for the infrastructure layer;
- Oracle outlined its role in operating the environment;
- SoftBank emphasized its financial backing.
Each announcement, viewed in isolation, can sound like a separate multi‑gigawatt initiative. In reality, they describe different facets of the same underlying build. And importantly, this is not unique to Stargate — similar multi‑angle, multi‑announcement patterns are becoming increasingly common across major AI infrastructure projects worldwide. This layered messaging contributes to a landscape where genuine incremental expansion becomes increasingly difficult to differentiate from multiple narratives referring to the same capacity.
Beware the Rise of “Braggerwatts”
If tracking real, shovel‑ready projects weren’t already challenging enough, a newer phenomenon has emerged to further distort expectations: “braggerwatts.”
These headline‑grabbing gigawatt declarations tend to be bold, aspirational, and often untethered from today’s practical constraints. They signal ambition more than bankability. While some may eventually break ground, many originate from firms without sufficient financing — or without the secured power required to energize campuses of this scale. In fact, the absence of power agreements is often the very reason these announcements become braggerwatts: compelling on paper, but unlikely to materialize.
Power is the Real Constraint—Not Chips
This leads directly to the most consequential source of uncertainty: power. As Microsoft CEO Satya Nadella put it in BG2 podcast, “You may actually have a bunch of chips sitting in inventory that I can’t plug in … it’s not a supply issue of chips; it’s actually the fact that I don’t have warm shells to plug into.”
Recent reports from Santa Clara County, Calif. underscored this reality. Silicon Valley Power’s inability to energize new facilities from Digital Realty and STACK Infrastructure revealed just how fragile power‑delivery timelines have become. Developers, competing for scarce grid capacity, increasingly reserve more power across multiple markets than they ultimately intend to use. Nicknamed “phantom data centers” by the Financial Times, these speculative reservations may be a rational hedging strategy — but they also clog interconnection queues and introduce yet another form of double counting.
Gantt Charts and Reality Checks
Making sense of real data center capacity — especially when announced timelines often compress multi‑year build cycles into optimistic one‑ or two‑year horizons — is challenging enough, but an even bigger issue is that, while announcements are rich in dollars and gigawatts, they are often strikingly vague as to when this capacity will actually be delivered. Several large AI‑era projects have publicized increasingly compressed “time‑to‑token” goals.
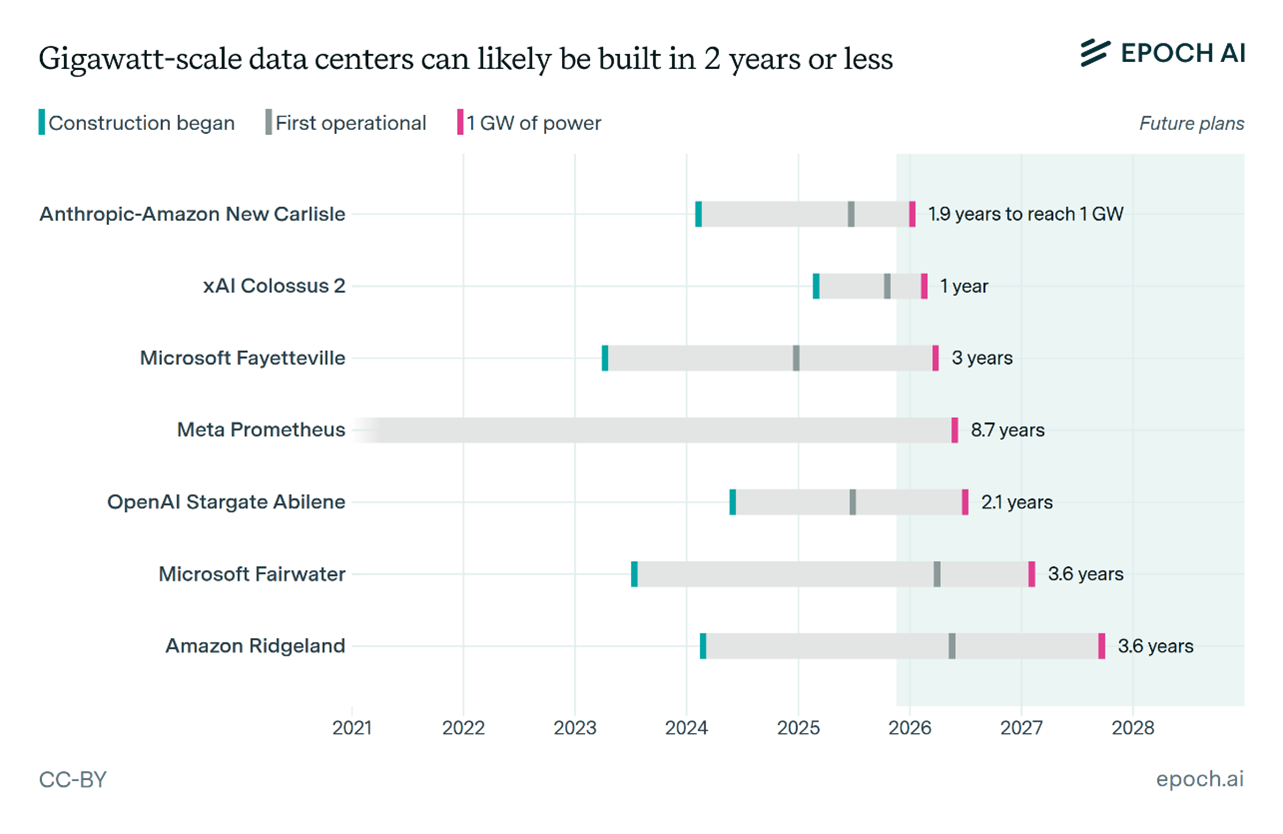
Recent mapping by nonprofit Epoch.AI, below, illustrates highly ambitious timelines to the first gigawatt of capacity. Yet the reality is far more measured. Most hyperscale and AI‑focused campuses are expected to phase in capacity over multiple years to manage engineering complexity, navigate permitting, and align with the risk tolerance of investors financing these developments.
True Modelling Requires Ground-true Data—Not Hype
Ultimately, this creates a disconnect between what is announced and what is genuinely achievable. Understanding true data center growth requires cutting through overlapping announcements, aspirational gigawatt claims, and speculative power reservations. By grounding expectations in semiconductor shipment volumes, verifiable construction progress, and secured power commitments, the industry can move beyond headline noise and toward an accurate view of the capacity that is truly on the way.