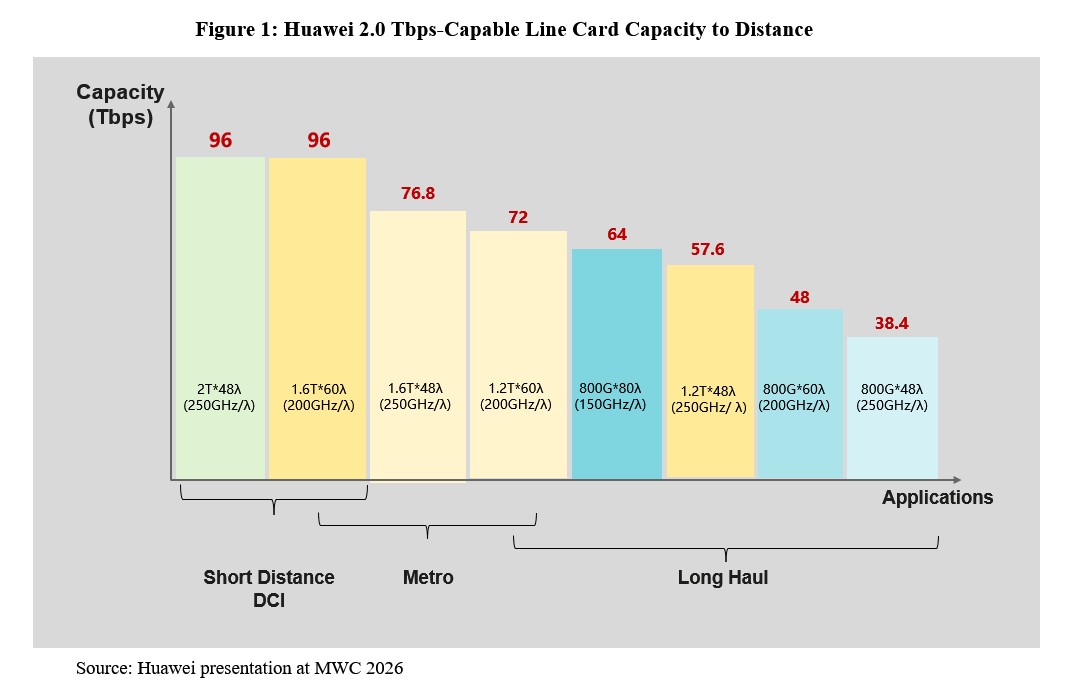
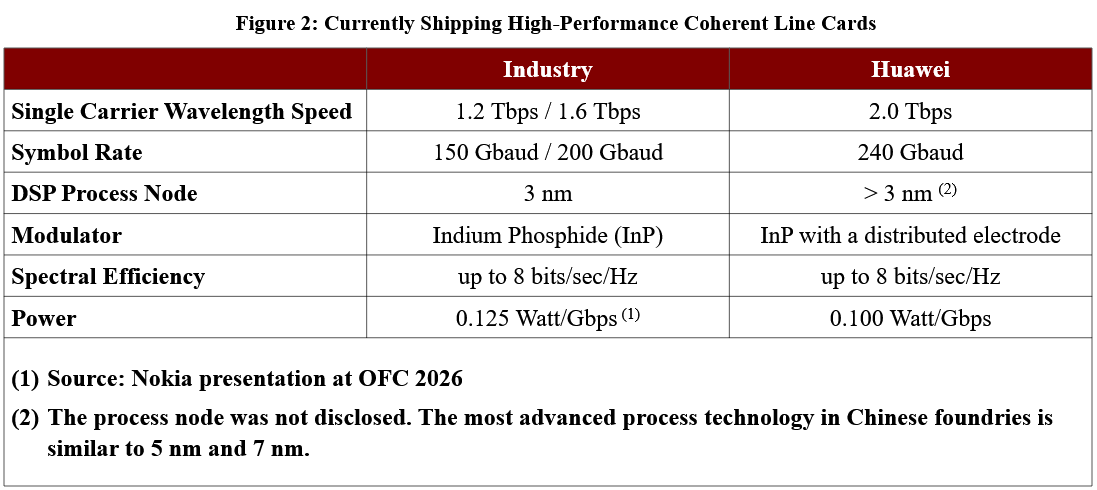
[wp_tech_share]
My first post-RSAC 2026 post argued that the more important story was not who could assemble the broadest category slide, but where security architecture was actually consolidating. This second blog goes deeper into the meetings themselves. Across 30+ conversations and events, from the largest platforms to early specialists, the same pattern kept recurring: the market is not collapsing into one monolithic control plane, but it is consolidating around a smaller number of them inside the existing pillars of identity, endpoint, network, cloud, application, data, and security operations. What stood out most was not only where those control planes are getting stronger, but how unevenly product maturity is catching up to the architecture being described.
Why the Meeting Set Mattered
The breadth of the meeting set mattered because it helped separate conference noise from patterns that repeated across very different vendors. The conversations ranged from companies such as Microsoft, Cisco, Google, Palo Alto Networks, Fortinet, Netskope, Cloudflare, and Broadcom to smaller and earlier companies with narrower starting points, such as AppGate, Cloudbrink, Helmet Security, Neon Cyber, and Zenarmor. That range made it easier to see which themes were structural rather than promotional. It also reinforced that the market still maps back to the existing taxonomy. Identity remains the trust plane. Endpoint remains the local execution plane. Network Security remains the distributed enforcement plane, with SASE increasingly the most ambitious effort to unify that plane across multiple edges. Cloud Security remains the workload and infrastructure context plane, with Cloud-Native Application Protection Platform (CNAPP) increasingly central to prioritization and remediation. Application Security remains the software assurance and remediation plane. Data Security is becoming more central in the policy and governance plane. Security Operations remains the operating layer that turns all of that into action.
That broader structure also helps make sense of another shift that surfaced repeatedly during the week. For much of the past two decades, enterprise security could increasingly assume a user-to-cloud model: users and endpoints on one side, centralized applications and data on the other, with the network in between. That assumption is weakening. Applications, data, and increasingly AI execution are becoming distributed again across endpoints, browsers, branches, private clouds, public clouds, and SaaS. That makes the control-plane problem less about how users reach centralized resources and more about how trust, telemetry, policy, and enforcement remain coherent as both actors and execution environments become more distributed.
AI Is Becoming a Force Multiplier for Action Governance
The most consistent message from the meetings was not that AI has created a wholly separate security universe. It was that AI is accelerating a broader move toward action governance. The market is spending less time asking how to secure a model in isolation and more time asking who or what is acting, what it can access, how it is observed, and what policy should govern that behavior.
Microsoft framed that shift through agent identity, registry, observability, and the extension of existing controls across Entra, Defender, Purview, Intune, and Sentinel into agentic environments. Cisco described AI Defense less as a point feature than as a trust layer that can sit behind multiple enforcement points. Even smaller specialists used the same logic, though from a much earlier starting point. In that sense, AI is not the only reason the architecture is shifting. It is an accelerant in both directions: it expands the threat surface enterprises need to govern, and it improves what security platforms can do in threat hunting, investigation, and response.
That distinction matters for vendors and market watchers. The real competitive question is not who can attach the term “AI security” to the most products. It is who can connect authorization, observability, policy, and control into an operating model that enterprises can actually use. The stronger vendors increasingly sounded less focused on treating AI as an isolated layer and more focused on absorbing it into broader control planes.
Data Security Is Becoming More Central
If one pillar moved closer to the center of gravity during the week, it was Data Security. That does not mean Data Security replaces the other pillars. It means it increasingly supplies the policy logic that the others enforce. The taxonomy already points in that direction by describing Data Security as the system of record for sensitive-data policy, exposure, and misuse, with enforcement or informed action extending into SSE, CNAPP, Email Security, and AI-related controls. The meetings reinforced exactly that point.
Cyera made the argument most directly by repeatedly framing AI security as fundamentally a data problem. Netskope extended its AI-security story from its existing cloud-security and SASE base into guardrails, red teaming, and posture. Zscaler treated inline AI governance as a natural extension of its control path because that is where traffic is already inspected. Skyhigh tried to widen the conversation from SSE into a broader, data-centric platform story anchored in hybrid enforcement, unified policy, and regulated-industry fit. Even where vendors differed on packaging or scope, the broader direction was similar: data security is becoming more central because the enterprise increasingly needs a policy that follows data consistently across the web, cloud, endpoints, email, and AI-related interaction points.
That is one of the clearest bridges between the control-plane discussion and the tracked markets. SASE increasingly intersects with Data Security because distributed enforcement without a coherent data policy does not scale well. CNAPP increasingly intersects with Data Security because workload and infrastructure context alone are insufficient if the policy layer around sensitive data is disconnected. Data Security is not becoming the control plane for everything, but it is becoming more central to how the others coordinate.
Platform Claims Are Facing a Harder Test
The week also made the platform question more concrete. The real issue is no longer whether a vendor participates in several adjacent markets. The harder question is whether it has shared policy, telemetry, analytics, and workflows across multiple control points. That was already the pre-RSAC test, and the meetings gave it more substance.
Microsoft remains one of the clearer examples of a platform claim grounded in coordination across identity, data, endpoint, and SecOps. Cisco is trying to absorb more of its AI, browser, branch, firewall, and SSE logic into a more unified operating model. Broadcom is trying to refactor endpoint, network, and data controls into a tighter story around integration and lower-friction deployment. HPE is pursuing additive convergence by reusing enforcement and technology across its security and networking portfolio without forcing abrupt platform retirement. At the same time, other vendors were candid about what they are not. Akamai was more comfortable with “ecosystem” than “platform.” Cloudflare sounded stronger on composability and deployment simplification than on any claim to own every adjacent control plane. Those differences matter. The market is beginning to separate real cross-plane coordination from adjacency marketing.
This is also where SASE and CNAPP should be understood more precisely. SASE matters because it is emerging as the strongest effort to unify the distributed enforcement plane within Network Security. CNAPP matters because it is becoming the leading context and prioritization plane within Cloud Security. Neither has to become the entire security architecture to matter much.
The Architecture Is Moving Faster Than Adoption
If the direction of travel became clearer, the maturity gap also became harder to ignore. Repeated probing on general availability, product depth, and production readiness often produced a more cautious answer than the show-floor narrative suggested. F5 was unusually direct in stating that the market is behind the marketing and that many customers are still not ready. Skyhigh Security clearly distinguished the more stable employee-guardrail problem from the still-fluid agentic AI problem. Cloudflare was candid about the fact that some current controls are still fairly coarse. HPE described deeper prompt and file-level controls as still coming over the next several months. Broadcom made the point differently, arguing that customer readiness and trust, not missing technology alone, remain the gating issue.
That does not undercut the strategic importance of the shift. It clarifies the market’s near-term state. The more realistic progression remains discovery first, monitoring second, selective enforcement third, and only then broader operational trust. In other words, the architecture is moving faster than adoption. That matters not only for product planning, but for how investors and ecosystem participants judge which narratives are likely to monetize sooner and which remain further out on the curve.
What it Means for Vendors, Investors, and the Ecosystem
The most useful takeaway from RSAC 2026 is not that cybersecurity is collapsing into a single category, nor that enterprises will become fully autonomous next year. It is that the centers of gravity inside the existing pillars are becoming easier to identify. Identity is broadening. The endpoint is regaining weight as execution moves closer to the device. Network Security is converging toward distributed enforcement, with SASE as the most ambitious unifying model in that pillar. Cloud Security is converging around CNAPP as a context and prioritization plane. Data Security is becoming more central as the policy layer for the other planes. Security Operations remains the operating layer that determines whether those planes produce outcomes.
For vendors, that raises the standard. Participation in more adjacencies is not enough. What matters is whether a vendor can anchor a meaningful control plane, coordinate effectively with the others, and reduce operational burden rather than merely relocating it. For equity analysts and market watchers, it sharpens the filter between real platform progress and conference theater. For service providers, silicon suppliers, and hardware ecosystem participants, it suggests that distributed execution, hybrid placement, and enforcement locality are likely to matter more over time, not less. That is the clearer signal that emerged from the week. That is the clearer signal that emerged from the week.
The third and final installment in this RSAC 2026 series, written for current Dell’Oro clients, will take that one step further by examining what these signals mean for vendor positioning, market structure, and the watch items ahead.
Related RSAC 2026 blogs:
Beyond the Acronyms: What I Will Be Watching at RSAC 2026